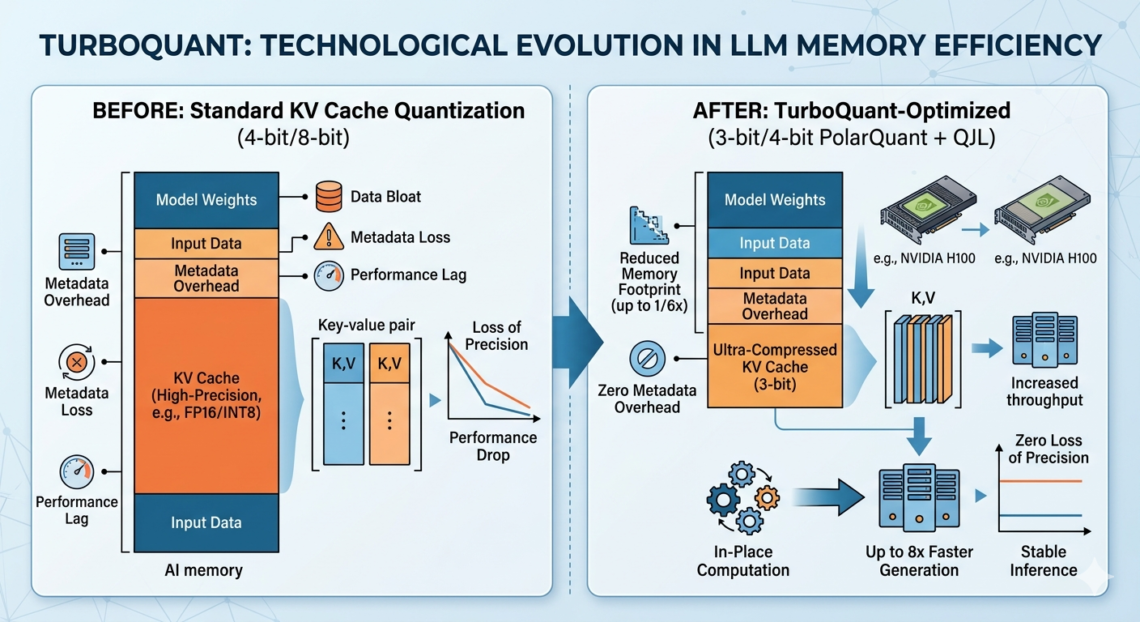
Google Researchが発表(2026年3月)した「TurboQuant」は、AI業界で決定的な転換点と呼ばれるほどの衝撃を与えています。推論時に用いられるAIの記憶(KVキャッシュ)を、質を落とさずに6分の1に圧縮し、さらに精度を落とさないで計算を8倍速くする技術(図)。ですが大きなポイントは3つ。① 「精度の低下」が実質ゼロ(PolarQuantとQJLにより、3ビット(元の1/6以下)まで削っても、元の精度を100%近く維持)、② 圧縮のための「余計な補正データ」がいらない=追加でメモリ消費がない、③圧縮したまま計算ができる=速度が最大8倍になる。メモリーが減るということはメモリーがいらなくなる方向よりはその分その資源を使いたくなるという方向に行きそうですし、Edge側での計算が軽くなってすそ野が広がるというような民主化の方向に活用されると考えると残念ながら長期的に考えると大きくメモリ需要が下がるという方向にはならないのかとは思います。こういったアルゴリズムからの根本的な改善はさらに進化が加速する方向に行くのであろうと考えると今後もまだまだ伸びしろがあると言えそうです。
Please follow and like us: