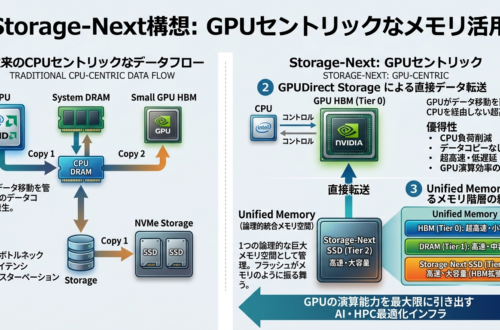
半導体では「半導体回路の集積密度が18か月から2年で2倍になる」というムーアの法則に従って進化が進んで来ましたが特に2010年代後半付近から減速。それを打開する後工程も巻き込んだチップの3次元化で性能の向上及びメモリ帯域の確保を図ろうというのが現状です。実際にその用途となるLLMに関しても進化が急速に進んでいる所に注目して俯瞰して法則を提唱した内容となっています。尺度は能力密度というもので特定の性能を達成するためにリファレンスモデルが必要とする「有効パラメーターサイズ」を、実際のパラメーターサイズで割った比率:パラメータ単位あたりの能力として表現されています。その結果はオープンソースLLMの最大能力密度は、約3.5ヶ月ごとにおよそ2倍になっているというものでムーアの法則(ハードウェアレベルの計算能力向上)と組み合わせることで、固定価格のチップ上で実行できる最大のLLMの有効パラメーターサイズは、約88日ごとにおよそ2倍になるということでムーアの法則と比較すると劇的なSpeedでモデル側の進化が起こっていることがわかります。どこまで続くのかというのはありますが単純に言ってしまえばモデルが軽くなればさらにさらに実質上計算できる能力が増えるわけで恩恵としてはエッジ側の能力向上が期待され、より普及が進んでいくのではと推測されます。まだキラーとなるものはさほどないにせよエッジAIとしてスマホなどの端末だけでなくロボット、車載といった分野で急速にAIの活用が進んでいくのではと思います。
今後のボトルネックは上記のように計算機性能の向上の方が遅いというところ考えるとKeyとなるのはパラメータ数というよりは「質の高い訓練データ」と「画期的なアーキテクチャ・訓練アルゴリズム」になっていくようです。1つ目に関しては能力密度の向上は主に「事前学習データの規模拡大と品質改善」にあったということでいかに新たな(正確な)データを食わせ続けるかというところと今後はデータを選別したり、高品位にAIが再合成するようなところがポイント。2つ目に単純な計算量増加(スケーリング)から「密度最適化訓練(Density-optimal training)」という方向に視点がシフトし、アーキテクチャや効率的な訓練なトレーニング手法というところがポイントとなりそうです。
それにしてもものすごい勢いで世界が変わりつつあるというのは間違いないところでいかに活用していくかというところを真剣に取り組んでいかないとあっという間に従来のやり方は陳腐化してしまいそうです。 その他、論文のまとめ↓
論文の要点:LLMの能力密度の指数関数的成長
1. 「能力密度」の導入
- 従来のスケーリング法則は、モデルサイズ(パラメーター数)の増加に伴い性能も向上することを示していますが、これは訓練とデプロイメントの課題(特に推論コスト)を引き起こしています 。
- この性能と効率性の間のトレードオフに対応するため、本論文では「能力密度(Capability Density)」という概念を導入しています 。
- 能力密度は、「モデルパラメーターの単位あたりに含まれる能力」として直感的に理解されます 。
- これは、モデルの性能と効率性の両方を統一的に評価するための指標となります 。
- 定義方法:能力密度は、特定の性能を達成するためにリファレンスモデルが必要とする「有効パラメーターサイズ」を、実際のパラメーターサイズで割った比率として定義されます 。
2. 「高密度化の法則(Densing Law)」の発見
- 能力密度の分析に基づき、本論文は「高密度化の法則(Densing Law)」という経験的観察結果を提示しています 。
- これは、LLMの最大能力密度が時間とともに指数関数的に成長しているというものです 。
- 具体的には、オープンソースLLMの最大能力密度は、約3.5ヶ月ごとにおよそ2倍になっています 。
- この進展は、わずか3.5ヶ月で、現在の最先端モデルと同等の性能を半分のパラメーターで達成できることを示唆しています 。
- 能力密度の向上は、主に事前学習データの規模拡大と品質改善によってもたらされています 。
3. 高密度化の法則が示す結論(Corollaries)
この法則から、LLMの開発と応用に関して以下の重要な結論が導かれます。
- 同等性能のLLMに必要なパラメーターサイズは指数関数的に減少する:能力密度が指数関数的に増加し、同等性能を保つために必要な有効パラメーターサイズが一定であるため、実際に必要なパラメーター数は指数関数的に減少します 。約3.5ヶ月ごとにおよそ半減しています 。
- 同等性能のLLMの推論コストは指数関数的に減少する:パラメーター数の指数関数的な減少は、推論時の計算コストの指数関数的な減少に直結します 。API価格のデータも、この傾向を裏付けています(約2.6ヶ月ごとにおよそ半減) 。
- 「高密度化の法則 × ムーアの法則」がエッジAIの可能性を広げる:
- 高密度化の法則(アルゴリズムレベルの効率向上)は、モデルの有効パラメーターサイズが約3ヶ月ごとに2倍になることを示します 。
- ムーアの法則(ハードウェアレベルの計算能力向上)と組み合わせることで、固定価格のチップ上で実行できる最大のLLMの有効パラメーターサイズは、約88日ごとにおよそ2倍の速さで成長しています 。
- これは、将来的には高性能なLLMがスマートフォンやPCなどのコンシューマー向けエッジデバイスで効率的に実行できる可能性を示しています 。
4. 開発戦略への提言:「密度最適化訓練(Density-optimal training)」
- 従来の単純なモデルの巨大化(スケーリング)は、短期間で陳腐化するモデルのコストとリターンを考えると、持続可能でも費用対効果が高くもありません 。
- このため、研究者は、訓練計算量を増やすことによる性能最適化から、効率的なモデルアーキテクチャ、高度な訓練アルゴリズム、洗練されたデータ前処理技術など、技術革新による密度最適化訓練へと焦点を移すべきだと提言しています 。
- また、大規模モデルと小規模モデルの相乗効果を活用し、大規模モデルによる知識蒸留やデータ合成で高密度な小規模モデルを開発し、小規模モデルで大規模モデルの訓練効率を向上させることが重要であると述べています 。
その他の観察
- ChatGPTリリース後の成長加速:ChatGPTのリリース後、モデル密度の増加率は約50%加速しました 。これは、LLM開発への投資増加や、質の高いオープンソースモデルの増加(特に小規模LLM)が要因です 。
- 効率的な圧縮の課題:モデルの枝刈りや量子化などの圧縮技術は、必ずしも密度向上につながるわけではなく、オリジナルのモデルよりも密度が低下する場合が多いことが示されています 。これは、圧縮プロセスにおける訓練不足が原因である可能性があり、圧縮モデルの十分な訓練が課題として挙げられています 。