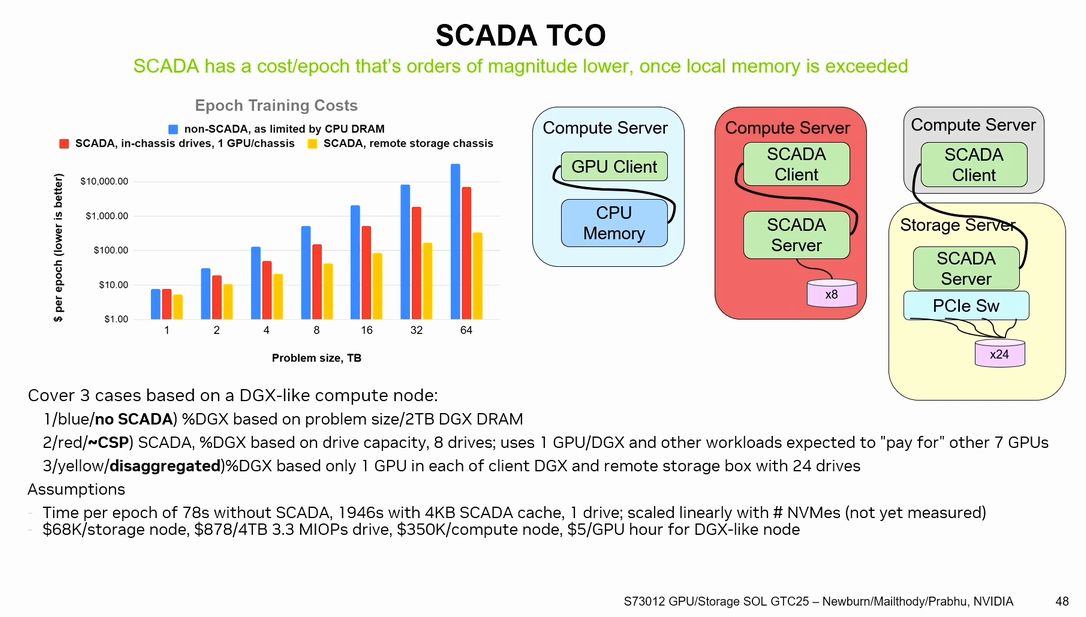
Speed-of-Light Data Movement Between Storage and the GPU
NVIDIAから構想がでてきているGPUを活用した大規模なデータアクセスを効率化する新しいアーキテクチャとして「SCADA (Scaled accelerated data access)」があり、紹介の様子が動画として公開されています。これは、大規模なデータセットがメモリに収まらない問題を解決するために、GPUをデータアクセスエンジンとして利用し、分散ストレージシステムとの連携を容易にすることで、データ処理効率を向上させるというものでいわばGPUを中心(入口)にしてデータセットへアクセス帯域を上げるというもの。CPUを介した分散メモリのシステムでなくGPU中心にデータが必要なところに供給させる考え方です。この構想ではメモリをデータに収めるという構想から一歩進んで収まらない巨大なデータセットをどのように処理するか?というところに大きな考え方のシフトがあり、従来のHBMからのデータ供給からNVMe SSDの活用というところに一歩踏み出してきており、この要求から不揮発メモリの世界を少し変えてくる可能性がありそうです。
「メモリに収まらない」データセットへの対応:従来のGPUメモリ容量(A100 GPUで80GBなど)では、数十GBから数十TBに及ぶような大規模なデータセット全体を保持することが困難なことが背景。
NVMe SSDの活用:データセットがGPUメモリに収まらない場合、NVMe SSDのような高速ストレージを活用することが重要になります。SCADAは、NVMe SSDからのデータアクセスをGPUが直接参照できるようにすることで、CPUを介した従来のアクセス方法よりもはるかに高いスループットと効率を実現。
GPUをデータアクセスエンジンとして利用:何十万ものGPUスレッドから、メモリに収まらないデータセットに対して、きめ細かなアクセスを効率的に行うことが可能で、ジェネレーティブニューラルネットワーク(GNN)のトレーニングやRetrieval-Augmented Generation (RAG) のような、計算負荷は低いがデータアクセスがボトルネックとなる新しいアプリケーションクラスに対応するために特に有効と考えられます。
新しいプログラミングモデルとAPI:GPUDirect StorageファミリーのcuFileやcuObjといった技術と連携し、新しいプログラミングモデルとしてSCADAを位置づけて推進。
キャッシュとメモリ管理の最適化:スケーラブルで高並列な、高スループットのソフトウェアキャッシュなどの機能を備え、データルックアップの高速化や透過的なデータ再利用によるメリットを享受し、I/Oボトルネックを軽減。
大きなデータセットを想定しているためNVM(不揮発メモリ)≒SSDを有効活用することを考えているわけですがやはりSSDのIOPS (Input/Output Operations Per Second)に対しては200M IOPS/GPUの要求。現最新世代のGen5 SSDではその2桁ほど下なので桁が違う製品の実現が必要となってきます。Storage-Nextという構想での各メモリメーカー、ベンダーとの連携を進めようとしています。従来のメモリのコスト指標であるGB/$ではなく計算効率、電力効率の指標であるIOPS/$というのがこれらの製品には求められそうですが果たして性能に対して価格がついてくるのか?というのも気になるところです。




